Laborjournal: Jürgen Bajorath Discusses the Evolving Role of Artificial Intelligence in Drug Discovery
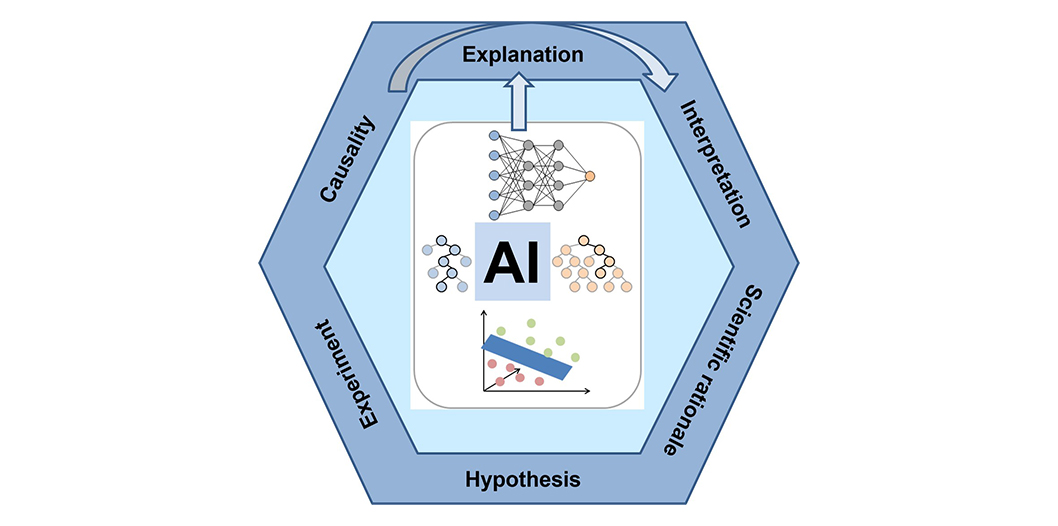
Artificial Intelligence is achieving increasingly impressive results in drug discovery. Yet as these models become more powerful, they also raise a fundamental scientific question: when do they produce reliable scientific insights, and when do they merely generate plausible predictions?